以前GPTsを紹介する記事を書いたのですが、せっかくなので、今日は作ってみたものをご共有してみたいと思います。

作ったもの
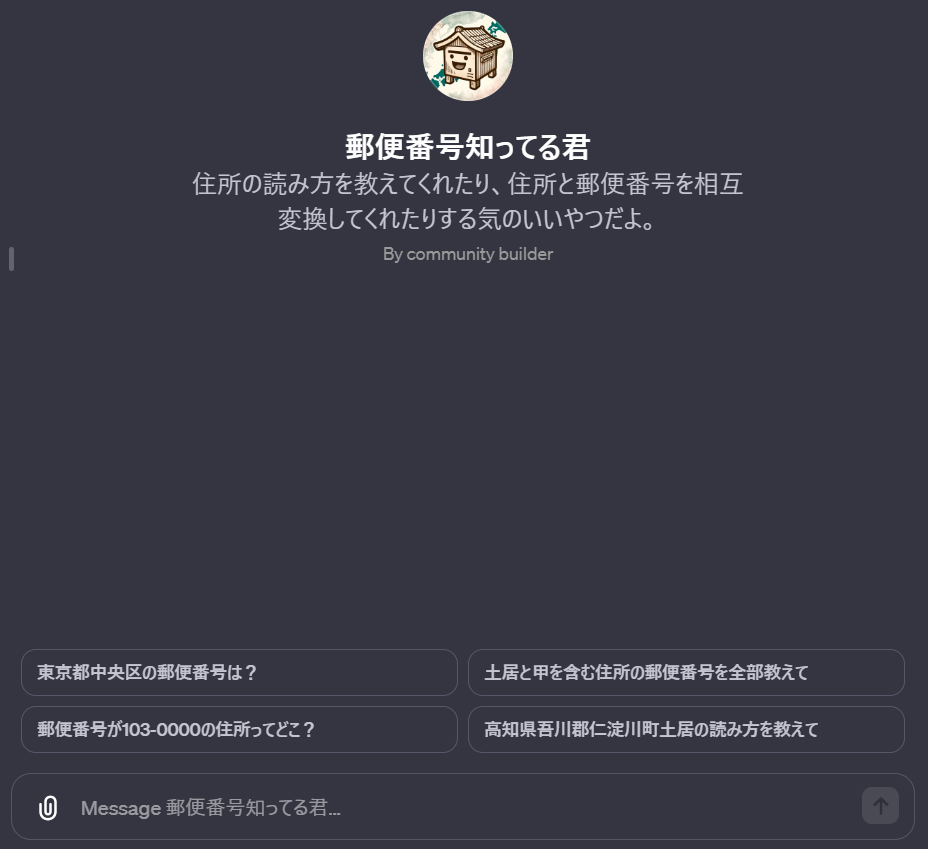
名前は「郵便番号知ってる君」にしました。その名の通り、主に以下の質問に特化したチャットボットです。
- 住所の読み方を教えてくれる
- 住所から郵便番号を教えてくれる
- 郵便番号から住所を教えてくれる
どう作ったか
まずはGPT Builderの質問に普通に答えていきました。特に凝ったプロンプトを投げたわけではありませんが、郵便局が公開しているutf_ken_all.csv(住所の郵便番号 1レコード1行、UTF-8形式)をアップロードした上で、必ずこのデータに基づいた回答をしろと指示したくらいです。

かつてKEN_ALL問題と呼ばれるほど悪名高かった郵便番号データですが、2023年6月から1レコード1行かつUTF-8形式版のCSVファイルが公開されたことで、少しだけマシになりました(それでも実用に耐えるようにするにはかなりの前処理が必要です…)。
本来は、このCSVを加工してAPI化した上で、Acitonsを使うのが王道だと思うのですが、プロンプトだけでどこまでできるのかを試したく、元データの修正は必要最低限にしています(この記事の最後に修正に使ったPythonコードも残しておきます)。
このCSVを読み込ませた上でプロンプトによるチューニングを色々試したのですが、うまく動いた指示と全然動かなかった指示があります。
- 郵便番号から住所を検索する際に、与えられた郵便番号の3桁目と4桁目の間に-が入っている場合は、それを除いた数字7桁で検索してください。
この指示はうまく動いてくれました。この程度のゆらぎであれば、良きに計らってくれるみたいです。
- utf_ken_all.csvの「住所」列には(1〜19丁目)というように間の数字が省略されている場合があるため、検索の際には間の数字を補ってください。例えば、「大通西3丁目」を検索した場合、「北海道札幌市中央区大通西(1〜19丁目)」を抽出する必要があります。
一方、この指示は全く機能しませんでした。例示しているようにken_allデータにはこれがあるので、ChatGPT側で補完してくれたらと期待したのですが難しかったようです。
注意点
今回はutf_ken_all.csvをKnowledgeとしてアップロードしていますが、使ってみると分かる通り、この情報は利用者に筒抜けになってしうため、機密情報や他人の著作物を勝手に使ったBOTを公開することがないように気をつける必要があります。
完成したもの
ということで、こちらが完成したBOT「郵便番号知ってる君」です。有料ユーザーの方は多分アクセスできると思うので良かったら試してみてください。
何気にアイコンがかわいいところが気に入っています!

おまけ
utf_ken_all.csvの加工に使ったPythonコードです。ちなみに、このコードのほとんどはChatGPTにサクッとドラフトしてもらいました。
import pandas as pd
japanese_postal_codes = pd.read_csv("utf_ken_all.csv", header=None)
# Step 0: Add headers to the dataframe
headers = [
"全国地方公共団体コード",
"旧郵便番号",
"郵便番号",
"都道府県名カナ",
"市区町村名カナ",
"町域名カナ",
"道府県名",
"市区町村名",
"町域名",
"一町域が二以上の郵便番号で表される場合の表示",
"小字毎に番地が起番されている町域の表示",
"丁目を有する町域の場合の表示",
"一つの郵便番号で二以上の町域を表す場合の表示",
"更新の表示",
"変更理由",
]
japanese_postal_codes.columns = headers
# Step 1: Delete the columns as specified by the user
columns_to_delete = [
"全国地方公共団体コード",
"旧郵便番号",
"一町域が二以上の郵便番号で表される場合の表示",
"小字毎に番地が起番されている町域の表示",
"丁目を有する町域の場合の表示",
"一つの郵便番号で二以上の町域を表す場合の表示",
"更新の表示",
"変更理由",
]
japanese_postal_codes.drop(columns=columns_to_delete, inplace=True)
# Step 2: Create '住所カナ' by concatenating the '都道府県名カナ', '市区町村名カナ', and '町域名カナ' columns
japanese_postal_codes["住所カナ"] = (
japanese_postal_codes["都道府県名カナ"]
+ japanese_postal_codes["市区町村名カナ"]
+ japanese_postal_codes["町域名カナ"]
)
# Step 3: Create '住所' by concatenating the '都道府県名', '市区町村名', and '町域名' columns
japanese_postal_codes["住所"] = (
japanese_postal_codes["都道府県名"]
+ japanese_postal_codes["市区町村名"]
+ japanese_postal_codes["町域名"]
)
# Step 4: Delete the original address columns
columns_to_delete = ["都道府県名カナ", "市区町村名カナ", "町域名カナ", "都道府県名", "市区町村名", "町域名"]
japanese_postal_codes.drop(columns=columns_to_delete, inplace=True)
# Export CSV
japanese_postal_codes.to_csv("modified_utf_ken_all.csv", index=None)
コメント